A CTO’s Guide to Distributed Systems: Why We Switched to Debezium
In this article, I want to talk about the suffering we endured to ensure data consistency in distributed systems and the solution we ultimately found.
To continue with the article, it seems necessary to first explain what a distributed system is.
What is a Distributed System?
In its simplest form, a distributed system is the general name given to organs located in different places, configured to keep an application alive, acting as if they are on a single network.
For instance, we might use MongoDB or MeiliSearch for searches, but our data resides in a PostgreSQL database; meanwhile, a self-hosted marketing application you use on the other side runs from its own MySQL server. All these databases and microservices work together for your application/site. We call these systems, working together like Teletubbies holding hands and watching the sunset, a Distributed System.
We can multiply this example: your application might be serving people in different locations from separate servers and databases, but you might be managing auth operations from a single point. Or perhaps you have an E-Commerce site, and your website’s database and your accounting software are not in the same database.
We generally call these types of situations a Distributed Structure.
Data Consistency
Okay, we have a distributed structure, and now we come to the part about how to ensure data consistency between databases in this structure.
The Drudgery of Polling / Cron Jobs
-
This is the most common system that comes to mind for keeping data up-to-date between two systems: let there be workers, let them run at certain times, and update the data. While this sounds nice, as the database grows, these queries start performing “Full Table Scans” and lock the CPU. New data arrives before the current data is updated, and we face unnecessary system load.
-
It never works as a real-time solution, and the gap between systems grows gradually. I say this knowing full well it will never be real-time in the true sense; in a system that updates slowly at certain intervals, up-to-date data remains merely a fantasy.
-
The difficulty of catching deleted records. When you say “let’s go update the data occasionally,” we are talking about a one-way update. It is impossible to see deleted, that is, hard deleted, data in the requests you make with select queries. This situation forces you to create extra, secondary control mechanisms.
Spaghetti Code and Coupling
Embedding logic into the application code to synchronize data.
Let’s say we have a service named UserService, and we need to update ElasticSearch when a user updates their
profile.
In this case, we go and add code that updates ElasticSearch inside the relevant update method within UserService.
As a result, UserService becomes a service that moves with different dependencies, not just performing user
operations.
If ElasticSearch responds slowly, the “Update” button works slowly. If code communicating with APIs is added and errors are returned from them, the “Update” button works incorrectly. As seen, the update button actually fulfilled its duty, but due to 3rd party plugins or spaghetti code, the code has become a huge burden.
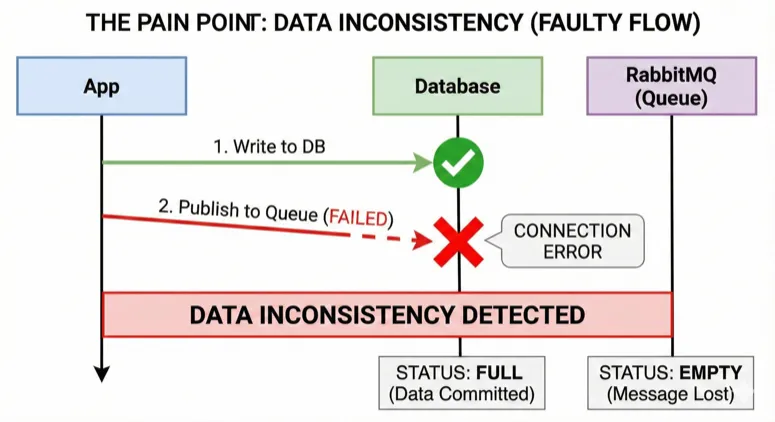
The Curse of Dual Write
Known in the literature as ‘Dual Write’, this issue is the most insidious enemy of distributed systems.
When I say, “Immediately after saving the user to the database, I’ll send an event to RabbitMQ, and then notify other systems with that event,” we are handing the entire ball to RabbitMQ. If our Queue structure crashes, the data you need remains in the Database, but it won’t be in your Queue system when it comes back online, which disrupts data consistency.
In summary, when an intermediate system goes offline and comes back, it needs to ingest the data consistently. Otherwise, there may be missing data or duplicate data.
Race Condition
Although thought to be rare, mix-ups in the sequence can occur in a chain of events connected one after another; a similar situation can happen in asynchronous structures.
Especially in situations where the possibility of updating in more than two places arises, if the sequence is not kept correct, an update operation might be run on top of data in one place before it has even opened in the other, resulting in an error.
The Solution: Taking the Pulse of the Database (CDC)
At the root of the problems I listed above (polling, dual write, spaghetti code) actually lies a single wrong approach: Constantly asking the Database, “What changed in you?”
However, the database already notes down its every breath (every operation) somewhere. PostgreSQL calls this the WAL ( Write Ahead Log), MySQL calls it the Binlog. Even if the database crashes, it gets back on its feet thanks to these logs.
Here is where the solution is hidden: Listening directly to these logs held by the database, without entering into the application code, without running queries that load the database, or setting up complex queue structures.
In the literature, we call this Change Data Capture (CDC).

Debezium
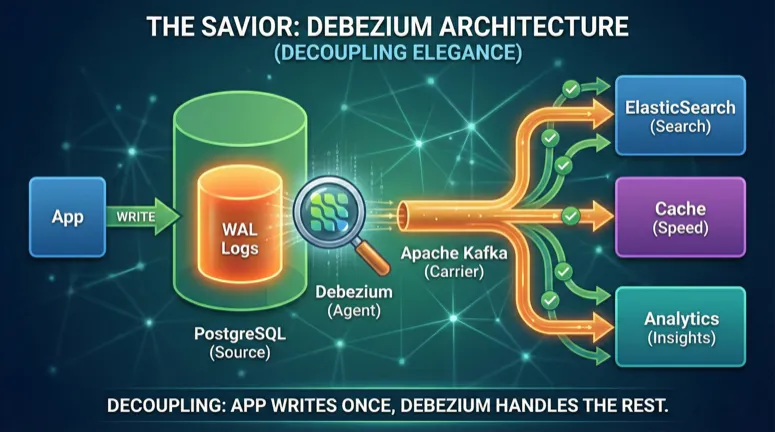
So, who will read these logs, and how? Parsing raw log files is an engineering task in itself. This is where **Debezium ** steps in.
Debezium, in simplest terms, acts like a “shadow” of your database. It introduces itself to the database as a ” replica” (copy server), and the moment the database engine writes to the logs saying “Look, this row was added, that row was deleted,” Debezium captures it.
It converts this captured raw data into a standard JSON format (or Avro) that everyone can understand and drops it into Apache Kafka.
Actually, let me continue with a good saying here: “If you are solving a problem with Kafka, congratulations, you now have two problems.” :)
So, what happens to our struggles mentioned above when we switch to this architecture?
-
Dual Write Ends: We no longer say “Write to DB and throw to RabbitMQ” inside the code. We only write to the DB. Debezium takes what is written to the DB in a guaranteed way and turns it into an Event. (The basis of the Outbox Pattern).
-
The Drudgery of Polling Ends: There are no
SELECT * FROMqueries. No extra load on the database engine. Debezium reads the logs; this operation is almost “free” for the database. -
Hard Delete Problem is Solved: When you delete a row from the database with
DELETE, the information “This ID was deleted” falls into the log file. Debezium captures this too and notifies you: “Look, this ID was deleted, you delete it from ElasticSearch too.” -
Nearest to Real-time: Instead of the 5-minute delay of a Cron job, you capture the data with a latency in the order of milliseconds.
How Does It Work?
Let’s imagine a simple flow chart to visualize it:
-
Application: Only sends the
INSERT INTO users...command to PostgreSQL. It finishes its job. -
PostgreSQL: Writes the data to disk and processes it into the Transaction Log (WAL).
-
Debezium (Kafka Connect): Instantly sees this change in the WAL file.
-
Kafka: Debezium drops this change as a message into the
db.public.userstopic. -
Consumers: ElasticSearch, Cache, Marketing Tools, etc., listen to this topic and take the data for themselves.
Thus, that complex orchestra we call the “Distributed Structure” now starts playing in sync, taking instructions from a single conductor (Database Logs).
Author’s Note (Through the Eyes of a CTO): Of course, “The only free cheese is in the mousetrap.” Although Debezium is a wonderful tool, it brings with it Kafka management, schema changes (Schema Evolution), and operational costs. However, if Data Consistency in scaling systems is keeping you awake at night, this price you pay remains very small compared to sleeping soundly.
Conclusion: Peaceful Sleep and Happy Teletubbies
To wrap up; building distributed systems is not like assembling Lego pieces. In Lego, the pieces are fixed; in software, those pieces are constantly moving, networks break, and servers get finicky.
What we call “seniority” in the industry is actually the sum of the nights we stayed up in front of databases exploding in prod environments and the crises we solved. The clearest thing I’ve learned in this process is this: “There is no perfect code, there is manageable chaos.”
Debezium and the CDC architecture is the modern approach that makes this chaos manageable, cleans up synchronization tasks that have turned into spaghetti code, and gives us the peace of a “single source of truth.” Sure, managing Kafka is harder than writing a Cron Job; but driving a Ferrari has a maintenance cost, right?
My priority in architectural decisions is always not just to save the day, but to sleep comfortably at night. Because good engineering is not just about the code working, but about the people keeping that code alive being at peace too.
Remember those Teletubbies we mentioned at the beginning, holding hands and watching the sunset? If you want to achieve their carefree happiness, keep the communication (network) between them strong and never leave data to chance.
Wishing you healthy, consistent, and commit-filled days.
Visuals generated with Nano Banana Pro. This article has been translated from my blog post written in Turkish, with the help of AI tools during the translation process.